Artificial Intelligence (AI) is no longer just a concept from science fiction; it has become an integral part of our daily lives. From virtual personal assistants like Siri and Alexa to recommendation systems on streaming platforms, AI is all around us. Its impact is also deeply felt in industries ranging from healthcare to finance, transforming the way we work and live. If you’re new to the world of AI development, this guide is your first step in demystifying the complex realm of artificial intelligence.
Understanding AI Development
At its core, AI development is the process of creating systems and algorithms that can perform tasks that typically require human intelligence. These tasks include recognizing patterns, making decisions, solving problems, and even understanding and generating natural language.

AI Development in Practice
To understand AI development better, let’s consider some real-world examples:
- Image Recognition: AI can be trained to recognize objects, faces, and even emotions in images. This technology powers facial recognition systems at airports and helps social media platforms tag your friends in photos.
- Natural Language Processing (NLP): AI can understand and generate human language. It’s what makes chatbots understand your queries and generates responses that sound like they were written by a human.
- Recommendation Systems: Platforms like Netflix and Amazon use AI algorithms to recommend movies and products based on your previous choices. They learn your preferences over time and improve their recommendations.
- Autonomous Vehicles: Self-driving cars rely heavily on AI to navigate and make real-time decisions on the road.
- Medical Diagnosis: AI can assist doctors in diagnosing diseases by analyzing medical images and patient data, often with remarkable accuracy.
AI Consulting
Many businesses recognize the potential of AI but lack the in-house expertise to implement it effectively. This is where AI consulting services come into play. AI consultants are experts in the field who can help businesses develop and deploy AI solutions tailored to their specific needs. They provide valuable insights, strategy, and hands-on assistance throughout the AI development process.
Why AI Development Matters
AI development matters for several reasons:
- Efficiency: AI can automate repetitive tasks, allowing humans to focus on more creative and complex work. This increases productivity and efficiency.
- Accuracy: AI can perform tasks with remarkable accuracy, often surpassing human capabilities. In medical diagnostics, for example, AI can analyze thousands of medical images quickly and with a high degree of precision.
- Personalization: AI can personalize user experiences, making recommendations and providing content tailored to individual preferences. This enhances customer satisfaction and engagement.
- Scalability: AI systems can handle massive amounts of data and can scale to meet growing demands. This is crucial in industries like e-commerce and finance.
- Innovation: AI fuels innovation by enabling the development of new products and services. It’s at the forefront of technological advancements.
Getting Started with AI Development
Now that you understand what AI development is and why it matters, let’s explore how you can get started if you’re a beginner.
1. Learn the Basics
Start by building a strong foundation in AI concepts and terminology. There are numerous online courses and tutorials available, such as those on platforms like Coursera, edX, and Udacity. Familiarize yourself with key terms like machine learning, neural networks, and deep learning.
2. Choose a Programming Language
Python is the most popular programming language for AI development. It has a rich ecosystem of libraries and frameworks, including TensorFlow, PyTorch, and scikit-learn, which are essential tools for AI developers. Learn Python and become comfortable with its syntax.
3. Explore Machine Learning
Machine learning is a subset of AI that focuses on training algorithms to learn patterns from data. Start by learning about supervised learning, unsupervised learning, and reinforcement learning. Understand the types of problems each can solve.
4. Hands-On Projects
Theory is important, but practical experience is crucial. Work on small AI projects to apply what you’ve learned. Start with basic tasks like image classification or text generation and gradually move to more complex projects.
5. Join AI Communities
Join AI forums, online communities, and social media groups. Engaging with others in the field can help you stay updated on the latest trends and technologies. It’s also a great way to seek help when you encounter challenges in your projects.
6. Consider Online Courses and Certifications
Consider enrolling in structured AI courses or earning certifications. These can provide a formal recognition of your skills and knowledge, which can be valuable when pursuing AI development as a career.
7. Experiment with AI Libraries
Experiment with popular AI libraries like TensorFlow and PyTorch. These libraries provide pre-built tools and resources for developing AI models, making it easier for beginners to get started.
Data Collection and Preprocessing for AI: Building the Foundation
Artificial Intelligence (AI) has revolutionized industries and technologies, from healthcare to finance, by making sense of vast amounts of data and automating complex tasks. However, AI is only as good as the data it’s trained on. To unlock the full potential of AI, one must understand the crucial steps of data collection and preprocessing. In this comprehensive guide, we’ll delve into the world of data, explore the intricacies of collecting and cleaning data, and highlight the significance of data quality in AI development.

The Foundation of AI: High-Quality Data
Before diving into the intricacies of data collection and preprocessing, it’s essential to grasp the fundamental role data plays in AI development. Data serves as the raw material from which AI models learn and make predictions. The quality of this data profoundly impacts the performance, accuracy, and reliability of AI systems.
The Significance of Data Quality
Data quality encompasses several key aspects:
- Accuracy: Data should be free from errors, inconsistencies, and inaccuracies. Inaccurate data can lead to incorrect AI predictions and unreliable results.
- Completeness: Data should be complete, with all required fields filled. Missing data can hinder model training and lead to biased results.
- Consistency: Data should be consistent across different sources and time periods. Inconsistent data can introduce noise and confusion into AI models.
- Relevance: Data should be relevant to the AI task at hand. Irrelevant or redundant data can increase computational overhead and make model training less efficient.
- Timeliness: For certain applications, such as fraud detection or stock market analysis, timely data is crucial. Delayed data can result in missed opportunities or incorrect predictions.
Data Collection Strategies
Effective data collection is the first step in preparing data for AI development. Depending on your project’s goals and requirements, you may need to employ various data collection strategies:
1. Web Scraping
Web scraping involves extracting data from websites and online sources. It’s commonly used for tasks like gathering product information, monitoring social media trends, or collecting news articles.
2. Sensor Data
In fields like IoT (Internet of Things), sensor data from devices like temperature sensors, cameras, and GPS units can provide valuable input for AI systems.
3. Surveys and Questionnaires
For tasks requiring human input or feedback, surveys and questionnaires are effective data collection methods. They are often used in social sciences and market research.
4. Public Datasets
Numerous public datasets are available for AI developers, covering a wide range of topics from healthcare to natural language processing. These datasets can be valuable resources for research and development.
5. Data Partnerships
Collaborating with organizations that possess the data you need can be an effective way to access high-quality data. This is common in industries like finance, where data is often proprietary.
Data Privacy and Ethics
When collecting data, it’s crucial to consider data privacy and ethical concerns. Ensure that you have the necessary permissions to collect and use the data, especially if it involves personal or sensitive information. Adhere to ethical guidelines and legal regulations governing data collection and use, such as GDPR in Europe or HIPAA in healthcare.
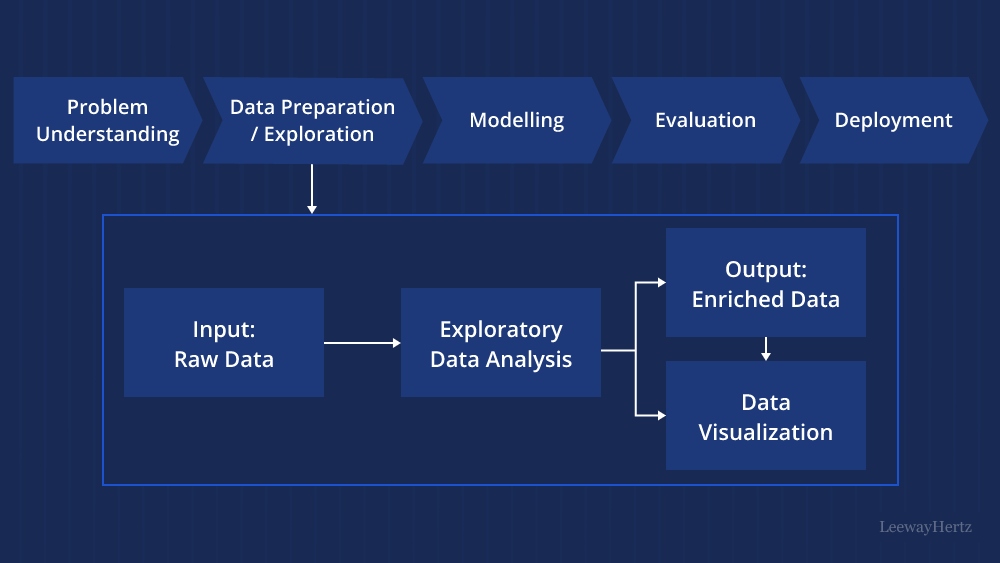
Data Preprocessing: Cleaning and Transformation
Once data is collected, it rarely comes in a pristine, ready-to-use form. Data preprocessing is the process of cleaning, transforming, and structuring data to make it suitable for AI model training. This step is often just as critical as data collection itself.
Data Cleaning
Data cleaning involves:
- Handling missing data by imputing or removing incomplete records.
- Detecting and correcting errors and outliers that can skew AI models.
- Ensuring consistency in data format and units.
Feature Engineering
Feature engineering is the process of selecting, creating, or transforming features (variables) in the data to improve the model’s performance. It involves:
- Selecting relevant features that contribute to the AI task.
- Creating new features through mathematical transformations or aggregations.
- Encoding categorical variables into numerical format for model compatibility.
Data Normalization and Scaling
Data normalization ensures that data values fall within a similar range, preventing certain features from dominating others during model training. Common techniques include Min-Max scaling and Z-score normalization.
Dealing with Imbalanced Data
In some cases, data may be imbalanced, meaning one class of data significantly outweighs the others. This can lead to biased model predictions. Techniques like oversampling, undersampling, or the use of specialized algorithms can address this issue.
Data Splitting
Before training an AI model, it’s crucial to split the data into training, validation, and test sets. This helps assess the model’s performance and prevents overfitting (when the model performs well on the training data but poorly on new, unseen data).
The Role of AI Consulting in Data Preprocessing
AI consulting services play a vital role in guiding businesses through the complexities of data collection and preprocessing. Here’s how AI consultants contribute:
- Data Strategy: AI consultants help businesses define a clear data strategy, identifying the data sources and types required for their AI projects.
- Data Quality Assessment: Consultants assess the quality of existing data sources, recommending improvements and data cleaning strategies.
- Data Governance: AI consultants establish data governance frameworks, ensuring that data is collected, stored, and processed in compliance with regulations.
- Feature Engineering: Consultants assist in feature selection and engineering, optimizing the data for AI model training.
- Model Selection: Consultants guide businesses in selecting the appropriate AI models based on their data and objectives.
- Performance Evaluation: Consultants evaluate model performance and provide insights into improving AI system accuracy and efficiency.
Machine Learning Algorithms and Model Building: A Comprehensive Guide
Machine learning, a subset of artificial intelligence, has witnessed unprecedented growth in recent years, transforming industries and revolutionizing the way we solve complex problems. At the heart of machine learning lies the diverse landscape of algorithms that enable computers to learn from data and make predictions. In this comprehensive guide, we’ll delve into the world of machine learning algorithms, exploring their types, applications, and the process of model building.
Understanding Machine Learning Algorithms
Machine learning algorithms are at the core of every machine learning application. These algorithms enable computers to recognize patterns, make predictions, and learn from data. The choice of algorithm depends on the nature of the problem you’re trying to solve, the type of data you have, and the desired outcome.
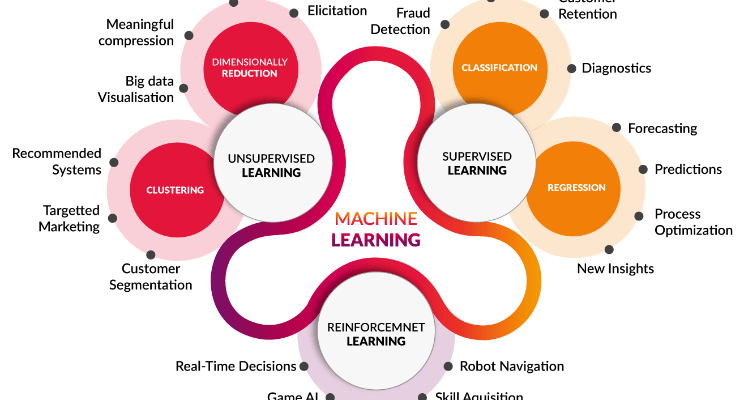
Types of Machine Learning Algorithms
Machine learning algorithms can be broadly categorized into three main types:
- Supervised Learning: In supervised learning, algorithms are trained on labeled data, where the input data is paired with the correct output or target variable. The algorithm learns to map input data to the correct output, making it suitable for tasks like classification and regression.
- Unsupervised Learning: Unsupervised learning algorithms work with unlabeled data, where the algorithm must discover patterns, clusters, or structure within the data. This type of learning is used in tasks like clustering, dimensionality reduction, and anomaly detection.
- Reinforcement Learning: Reinforcement learning is focused on training agents to make decisions in an environment to maximize a reward signal. It’s commonly used in applications like game playing, robotics, and autonomous systems.
Popular Machine Learning Algorithms
Within these categories, numerous machine learning algorithms exist, each with its unique strengths and weaknesses. Some of the most popular algorithms include:
- Linear Regression: Used for regression tasks where the goal is to predict a continuous numeric value.
- Logistic Regression: Used for binary classification tasks, such as spam detection or disease diagnosis.
- Decision Trees: Used for both classification and regression tasks, decision trees provide a structured way to make decisions based on input features.
- Random Forest: An ensemble algorithm that combines multiple decision trees for improved accuracy and robustness.
- Support Vector Machines (SVM): Used for classification tasks, SVMs aim to find the hyperplane that best separates data into different classes.
- K-Nearest Neighbors (K-NN): A simple classification algorithm that assigns a data point to the class most common among its k-nearest neighbors.
- K-Means Clustering: A popular unsupervised learning algorithm used for clustering data into groups.
- Neural Networks: Complex models inspired by the human brain, neural networks are at the forefront of deep learning and are used in a wide range of tasks, from image recognition to natural language processing.
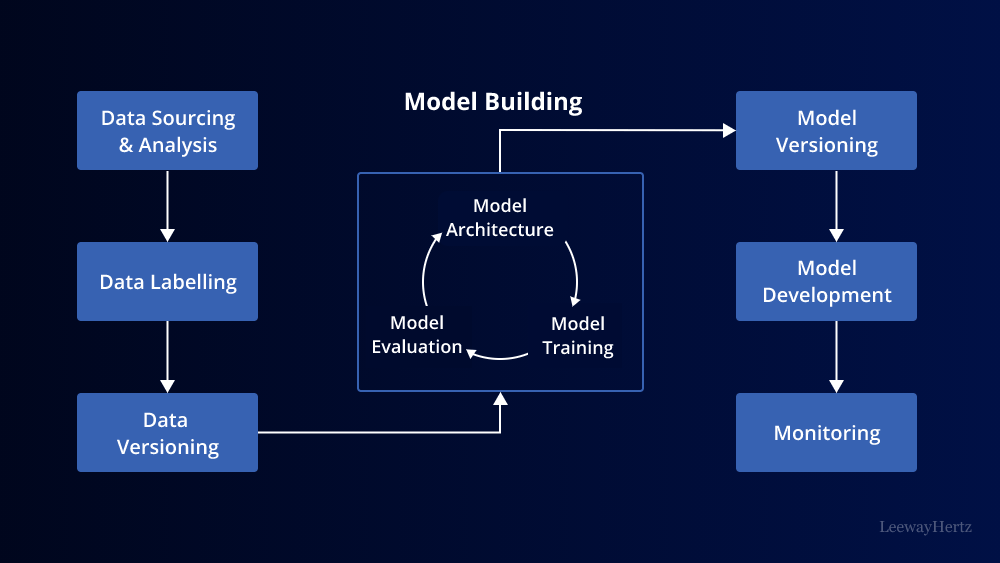
Machine Learning in Practice: Model Building
Now that we’ve gained an understanding of machine learning algorithms, let’s explore the practical aspects of model building. Building a machine learning model involves several key steps:
1. Data Preparation
Before you can build a machine learning model, you need to prepare your data. This includes:
- Data Cleaning: Handling missing values, dealing with outliers, and ensuring data quality.
- Feature Engineering: Selecting relevant features and transforming them to improve model performance.
- Data Splitting: Dividing your data into training, validation, and test sets to assess and evaluate your model.
2. Model Selection
Choosing the right machine learning algorithm for your problem is crucial. Consider factors such as the type of task (classification, regression, or clustering), the volume of data, and the nature of the data (structured or unstructured).
3. Model Training
Model training involves using the training data to teach the algorithm to make predictions or classify data accurately. During training, the algorithm learns the patterns and relationships in the data.
4. Hyperparameter Tuning
Most machine learning algorithms have hyperparameters that control the learning process. Tuning these hyperparameters is essential to optimize the model’s performance. Techniques like grid search or random search can be used for hyperparameter tuning.
5. Model Evaluation
Once the model is trained, it’s essential to evaluate its performance using the validation set. Common evaluation metrics include accuracy, precision, recall, F1-score, and mean squared error, among others.
6. Model Testing and Deployment
After satisfactory performance on the validation set, it’s time to test the model on the test set to ensure it generalizes well to new, unseen data. Once you’re confident in the model’s performance, you can deploy it in real-world applications.
Machine Learning Algorithms in Action
Machine learning algorithms find applications in a wide range of domains. Here are some real-world examples:
1. Healthcare
Machine learning algorithms are used for disease prediction, medical image analysis, drug discovery, and personalized treatment recommendations.
2. Finance
In finance, algorithms are employed for fraud detection, credit scoring, algorithmic trading, and risk assessment.
3. Natural Language Processing (NLP)
NLP algorithms power chatbots, language translation, sentiment analysis, and text summarization.
4. Autonomous Vehicles
Self-driving cars rely on machine learning algorithms to navigate, make real-time decisions, and avoid obstacles.
5. E-commerce
Recommendation systems use machine learning to suggest products, personalize content, and improve user experience.
The Role of AI Consulting in Model Building
AI consulting services play a pivotal role in guiding organizations through the complex process of model building. AI consultants offer expertise in:
- Problem Definition: Defining clear objectives and selecting the right machine learning algorithms for the task at hand.
- Data Strategy: Developing data collection and preprocessing strategies to ensure the availability of high-quality data.
- Model Selection: Recommending the most suitable machine learning algorithms based on data and business goals.
- Hyperparameter Tuning: Optimizing model performance through hyperparameter tuning and experimentation.
- Model Evaluation: Conducting rigorous model evaluation and testing to ensure reliability and robustness.
- Deployment: Assisting in deploying machine learning models in real-world applications.
Conclusion
Machine learning algorithms and model building represent the heart of artificial intelligence and its real-world applications. As the field of AI continues to evolve, understanding the principles of different machine learning algorithms and the process of model building is essential for both beginners and experienced practitioners. With the right knowledge and techniques, you can harness the power of machine learning to solve complex problems, make data-driven decisions, and drive innovation in a wide range of industries. Whether you’re predicting customer behavior, diagnosing diseases, or navigating autonomous vehicles, machine learning algorithms are your key to unlocking the potential of AI in the modern world.